Human oversight that helps you scale AI agents without scaling risks
Testlio’s AI agent testing solution combines human-in-the-loop (HITL) validation, proprietary methodologies, and an AI-powered platform to help you release safer, more reliable agentic experiences at global scale.

Test how your agent acts in the real world, not just what it says
An agent that performs in a controlled run can still break the moment it meets a real device, a regional payment flow, or a user who doesn't follow the script. Testlio's global community tests with that context in mind, so your agents perform in the moments that matter.
Turn complex agentic behavior into a readiness signal
Every assessment includes our proprietary confidence score, LeoPulse™, to help you determine if your AI agents are production-ready. Scored on a scale from 0-100, it measures whether the agent completed the correct workflows, used the appropriate tools, respected permissions, acted safely, and produced a verifiable outcome. With risk-based weighting and built-in safeguards, LeoPulse informs release decisions and serves as a benchmark for measuring improvements.

A framework built, not adapted, for agentic systems
AI agents introduce failure modes that traditional QA was never designed to catch. So we built a framework with a decomposition-first approach, breaking each agent down into the workflows, decisions, and actions it actually performs, so testing reflects how your agents behave in the real world, not how they look in a demo. You get:
Expert-designed and contextual evaluation
Multi-region and language validation
Scalable human-in-the-loop validation
Automation-supported execution
Comprehensive reporting
Fully managed testing model
Validate end-to-end agent interaction arcs
Testing a single response tells you little about an agent that strings together decisions, tools, and actions to finish a task. We validate the full arc, from the first user input to the final completed action, so you see how your agents perform across everything a real workflow demands.
Agent behavioral baselining
Establish a clear starting point for how your agent, or network of agents, handles the common tasks that matter most to your business.
Coverage quality scoring
Get a health score across 11 distinct coverage and functional areas, so you know exactly where your agent is strongest and where it falls short.
Task success validation
Measure the precise percentage of workflows your agent completes fully, reliably, and safely.
Safety and release guardrails
Surface the critical failures and risks that are serious enough to cause reputational damage or to stop a public release before it ships.
Tool and action auditing
Get evidence of every time your agent picked the wrong tools, entered incorrect details, took unsafe actions, or didn't complete back-end tasks.
Agent decomposition and testability assessment
Map your agent's workflows, tools, APIs, data sources, roles, permissions, logs, traces, and state validation points before testing begins.
Strategic improvement roadmap
Get practical, expert-led next steps for fixing issues, re-testing, and deciding whether your agent is ready for users.

A managed community, trained to test AI agents
Testlio’s global and managed community includes experts who are highly vetted, skilled, and intentionally matched to your project through LeoMatch™ based on your specific needs. They bring the domain knowledge, in-market familiarity, and language fluency needed to catch cultural, linguistic, and regional issues that others miss. Our community receives structured training to evaluate end-to-end agent actions, from understanding user intent to producing outcomes supported by evidence, so teams get a complete picture of their agents’ performance.
An AI-powered platform for complete transparency and control
Testlio's AI-powered platform, LeoCore™, intelligently orchestrates testing from start to finish. It handles everything from sourcing talent through LeoMatch™ to managing test cycles and analyzing results. With LeoInsights™ delivering real-time, actionable recommendations and built-in integrations like Jira and TestRail, results flow into the tools your team already uses, so nothing gets lost in translation.
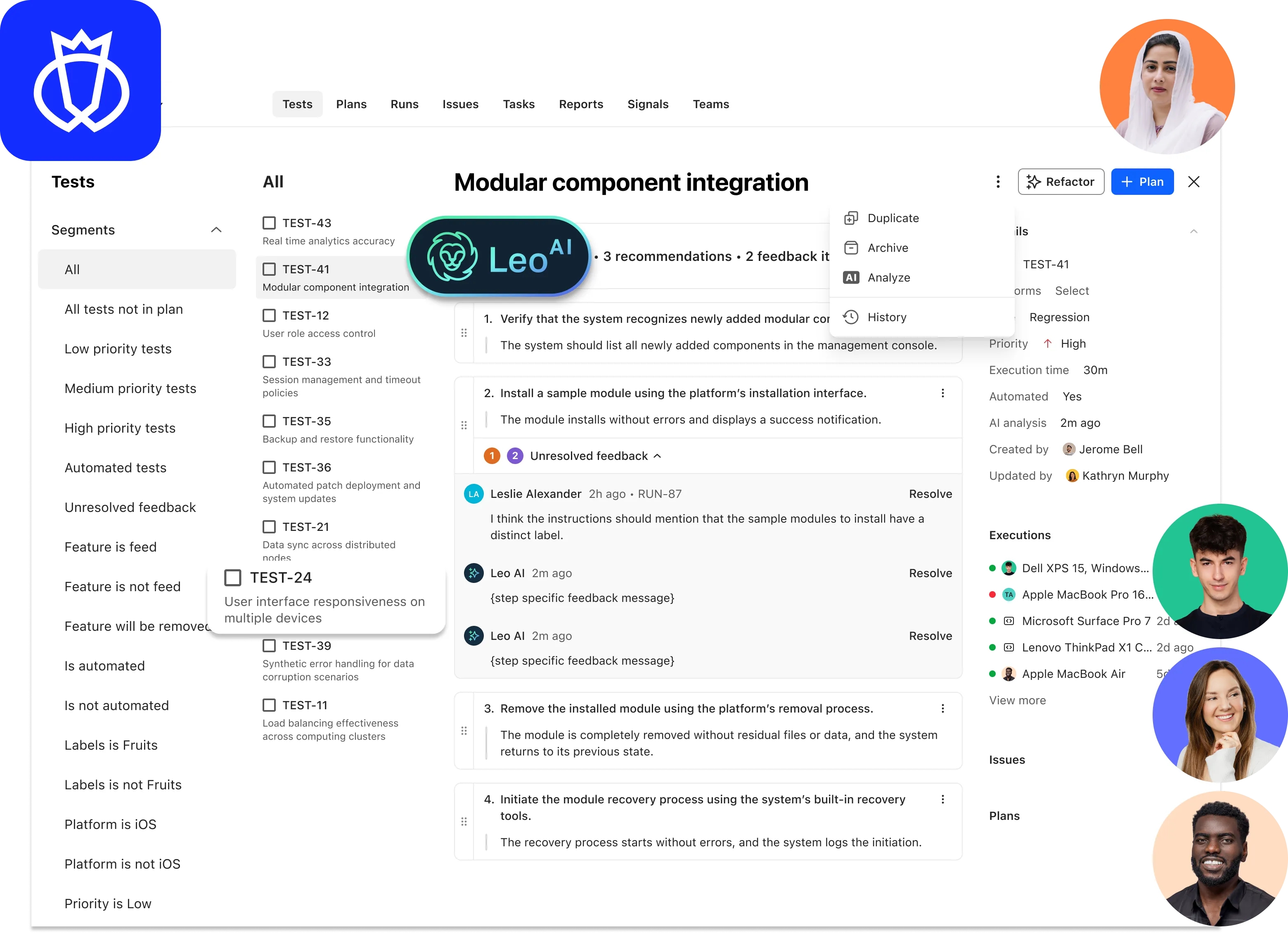

Test everything else that AI touches in your customer journey
Whatever shape your AI takes, Testlio's end-to-end, human-led AI testing solutions validate the full range of systems and use cases your product depends on, so you protect your brand and earn the customer loyalty that keeps them coming back. From generative AI features, chatbot interactions, RAG pipelines, predictive models, and recommender engines, we help you test it all quickly and at global scale.
Release agents based on evidence, not optimism
Most teams ship agents on a hunch that they'll hold up. Testlio replaces the hunch with proof. We combine the benefits of a global tester community with the rigor of a managed model so you can focus on building better products.
End-to-end execution
Dedicated client support
Built-in security

Flexible coverage
Intentional staffing
Let’s make sure your agents do exactly what you want them to.
Frequently asked questions
Unlike automated tools and LLM-as-a-judge frameworks, we leverage a combination of human-in-the-loop validation with automation-supported execution to help enterprises scale agentic AI testing responsibly. We don’t rely on a random pool of testers. Our managed community is trained to find the unique ways agents fail. Paired with our structured decomposition-first approach, our testers run realistic workflow scenarios and evaluate the full path from intent to outcome. The results are translated into LeoPulse™ readiness, helping customers understand where the agent is ready, improving, or regressing.
Workflow scenarios are tailored to your specific user paths and established workflows. Testlio’s in-house experts work with you to identify your agent structure, what tasks it is expected to complete, the tools and workflows it must use, the data sources and approvals it should seek, the evidence it must produce, and more. This data is then used to create workflow scenarios across 11 coverage areas to help teams thoroughly validate agent actions end-to-end, not just the final output.
LeoPulse is our proprietary confidence score for agent release readiness, scored 0 to 100. It reflects whether your agent completed the correct workflow, used the appropriate tools, respected permissions, acted safely, and produced a verifiable outcome. Risk-based weighting keeps critical issues from being masked by strong performance elsewhere, and the score is trackable over time as a benchmark for improvement.
We map each agent's workflows, tools, and handoffs before testing begins, then validate how they perform individually and together. That decomposition lets us pinpoint where a breakdown happens in a chain, whether it's a single agent, a handoff, or a shared tool or data source.
Yes. Our community spans 150+ countries and 100+ languages. We match testers to your target markets so testing reflects the real cultural and linguistic context your users bring. They test across 600k+ devices and 800+ payment methods in real-world conditions, so your app always performs in moments that matter.
Timelines depend on your product complexity, scope, and onboarding requirements. We involve our delivery team early to align on goals and get your first test cycle moving as quickly as possible. We find most engagements start within 15 days.
Testlio's pricing model is designed to help you get the most out of your partnership with us. It’s built on two factors. A platform fee covers your LeoCore access — tester matching, reporting, integrations, orchestration and your account management team. An annual consumption fund covers the testing work itself. Whether you need quality management, specialized testers, experts in a specific region, or a specific number of testing hours, your consumption fund supports it. What's included in each scales with your package: Essential, Advanced, or Enterprise.
LeoAI Engine™, the proprietary intelligence layer that powers our Platform, orchestrates the entire testing process, from test runs and work opportunities to recruitment, application, and results. By automatically surfacing the best-fit participants for each engagement, streamlining onboarding, and learning from historical project data, it removes friction and enhances precision at every step. This means fewer manual tasks, more strategic oversight, and dramatically improved speed and scale.
