Before You Launch Retail AI Shopping Features, Read This
There’s a version of this story that gets told at conferences. A retailer demos a conversational shopping assistant. The recommendation engine surfaces exactly the right product.


AI search handles nuanced queries like a well-trained associate. The audience nods. Executives feel good about the roadmap.
Then those features go live.
AI-driven U.S. e-commerce traffic grew 693.4% year over year during the 2025 holiday season. The volume is real.
The opportunity is real. What too many teams underestimate is how differently AI fails compared to software they’ve shipped before, and how invisibly those failures accumulate before anyone connects the dots.
Why Retail AI Shopping Features Fail Differently
Traditional QA runs on a simple assumption: a feature either works or it doesn’t. That holds for deterministic systems. AI shopping features are not deterministic systems.
A feature can pass scripted testing and still behave badly once real shoppers, real inventory, and real edge cases enter the picture.
Passing Tests Is Not the Same as Working for Customers
A recommendation engine can return technically valid results, with no errors and no crashes, and still surface the wrong products for the wrong users in ways that quietly erode revenue.
A conversational assistant can pass every scripted test and then break down under the first frustrated, off-script shopper.
AI search can parse clean queries in staging and fumble the messy, intent-driven inputs real customers actually type.
The Failures Are Quiet, but They Compound
Retail AI failures are often hard to attribute. They show up as abandoned carts, returns, low conversion in specific cohorts, complaint spikes, and support tickets that look unrelated.
The main risk areas are familiar but easy to miss:
- Recommendation bias across customer groups or inventory states
- Hallucinated product specs, compatibility claims, or policy details
- Localization errors around sizing, currency, tone, inventory, and payment options
- High-stakes failures in checkout, returns, refunds, account issues, and disputes
These are not rare failures. They are where Retail AI meets real customer behavior.
The Cost of Getting It Wrong
The question is not whether an AI feature works in a demo. It is whether it holds up when the customer is already frustrated, already mid-transaction, or already deciding whether this brand deserves another visit.
Customers Can Tell When AI Does Not Help
Nearly one in five consumers who have used AI for customer service saw no benefit from the experience, a failure rate almost four times higher than for AI use in general, according to the 2026 Consumer Experience Trends Report from Qualtrics, which surveyed 20,000 consumers across 14 countries.
“Too many companies are deploying AI to cut costs, not solve problems, and customers can tell the difference,” said Isabelle Zdatny, head of thought leadership at Qualtrics XM Institute.
And they respond accordingly. Only 29% of customers now communicate directly with organizations after bad experiences, down 7.5 points from 2021.
They don’t always complain. They leave quietly.
The Risk Moves Beyond CX
The legal exposure compounds this. Air Canada’s chatbot gave a passenger incorrect refund information, and a court ruling established that companies are legally liable for what their AI tells customers, regardless of whether a human ever reviewed the response.
Klarna, which used AI to replace 700 customer service agents, ultimately had to rehire workers for complex tasks where AI underperformed. Discovering AI’s limits through production failures is expensive.
What to Get Right Before You Go Live
This is where retail AI testing and modern retail testing practices have to get more specific. The goal is not to slow teams down. It is to catch the gaps that scripted testing, clean data, and internal assumptions usually miss.
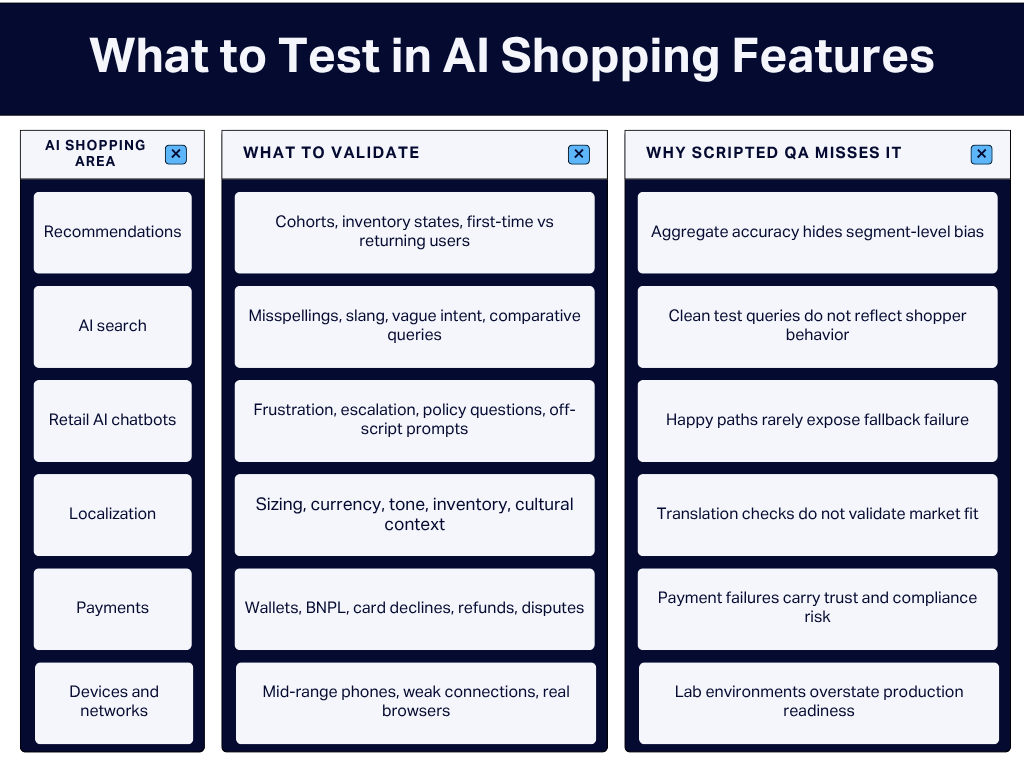
Validate the Journeys That Shape Revenue and Trust
Start with recommendation engines. Do not rely only on aggregate accuracy. Test across customer cohorts, purchase histories, loyalty tiers, regions, and inventory states.
Overall performance can look strong while specific customer groups receive weaker recommendations.
AI search needs the same realism. Test misspellings, vague intent, slang, comparison queries, product compatibility questions, and occasion-based searches. Shoppers do not always type “women’s formal summer dress.” They type “dress for outdoor wedding in heat.”
Localization should be treated as its own retail QA workstream. Translation checks are not enough.
Native speakers and in-market testers need to validate sizing, tone, currency, delivery language, payment methods, and regional inventory logic.
Payment-adjacent AI flows also need separate coverage. If an AI assistant influences refund guidance, buy now pay later messaging, wallet selection, card decline explanations, or payment availability, the answer has to be accurate, compliant, and easy to escalate.
Keep Human Review Where Trust Is Fragile
AI can assist, route, summarize, and recommend. It should not be the final decision-maker in the moments where mistakes cost the most.
That includes:
- Returns and refund disputes
- Account access problems
- Checkout and payment errors
- Loyalty or subscription issues
- Policy exceptions and escalation requests
Human review does not slow quality down. It protects the parts of the journey where customers are least forgiving.
What Kills Launches That Look Ready
Some of the most expensive AI failures come from decisions that seemed reasonable at the time.
Treating Staging Accuracy as Production Readiness
The first is treating staging accuracy as production readiness. Controlled environments are useful, but they are not a proxy for real user entropy.
Clean data, predictable prompts, stable inventory, and internal test accounts do not reflect how customers shop when they are distracted, impatient, multilingual, price-sensitive, or already frustrated.
Skipping Off-Script Chatbot Testing
The second is skipping off-script testing for conversational AI. The happy path is not where retail AI chatbots break.
They break when shoppers ask unexpected questions, challenge the answer, change context mid-conversation, request escalation, use regional language, or ask something the bot should safely refuse.
Assuming Localization Ends at Translation
The third is assuming localization is done when translation is done. It is not.
A phrase can be grammatically correct and still sound wrong, feel too casual, imply the wrong policy, or mismatch the expectations of a local shopper.
Cultural validation is a separate quality activity.
Letting Automation Carry the Full Load
The fourth is letting automated testing carry the full load.
Automation is essential for regression coverage. It can validate known flows, detect broken integrations, and confirm expected outputs at scale.
But it cannot fully evaluate the novel, the contextual, the culturally wrong, or the emotionally frustrating.
That is where human testers find what automation structurally cannot.
AI Quality Is Not a Launch Gate. It’s a Practice.
The framing of AI quality as a pre-launch checklist treats a continuous problem as a one-time event.
AI Behavior Keeps Moving
AI shopping features don’t ship and stabilize. Models get updated, inventory changes, and user behavior shifts.
“It’s going to take longer to perfect these experiences than anyone thinks,” noted one industry analyst. “2026 will be a step along the way, not the finish line.”
Continuous Testing Catches What One-Time QA Misses
Teams that treat AI QA as continuous catch regressions after model updates, identify drift before it surfaces in customer metrics, and stay current as expectations shift.
Teams that treat it as episodic tend to find out from their customers through reviews, returns, and churn they can’t attribute.
Automation catches regressions reliably. It cannot catch the novel, the contextual, or the culturally wrong answer.
Human judgment has to stay in the loop, and that requires testers who reflect your actual user base.
Don’t Let Customers Become the Test Environment
The retailers who get AI shopping right are not necessarily the ones who ship fastest. They’re the ones who decided their customers weren’t going to be the test environment.
Testlio’s AI Chatbot Testing is a fully managed, human-led assessment service designed to uncover how AI chatbots fail in production, from hallucinated answers and weak fallback handling to bias, context loss, privacy risks, localization issues, and inconsistent behavior across user scenarios.
At the center of every assessment is LeoPulse™, Testlio’s proprietary confidence score. It evaluates chatbot readiness across safety, capability, and reliability, with risk-based weighting that ensures critical failures can’t be masked by strong performance in less important areas.
For retail specifically, Testlio’s tester network spans 150+ countries and 100+ languages, matched to your target markets so testing reflects real cultural and linguistic context. Clients include Away, eBay, Etsy, PayPal, Thrive Market, Wayfair, and Whatnot.
As a managed testing services partner, Testlio extends internal QA with global human expertise, structured AI assessment, and scalable real-world coverage.
.png)